Generating vivid and diverse 3D co-speech gestures is crucial for various applications in animating virtual avatars.
While most existing methods can generate gestures from audio directly,
they usually overlook that emotion is one of the key factors of authentic co-speech gesture generation.
In this work, we propose EmotionGesture, a novel framework for synthesizing vivid and diverse emotional co-speech 3D gestures from audio.
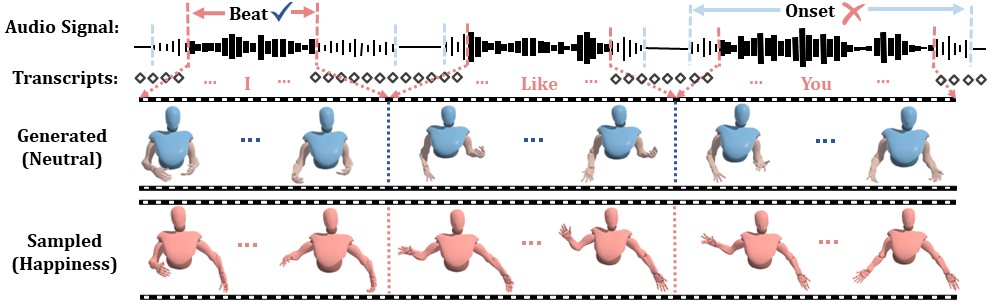
Considering emotion is often entangled with the rhythmic beat in speech audio,
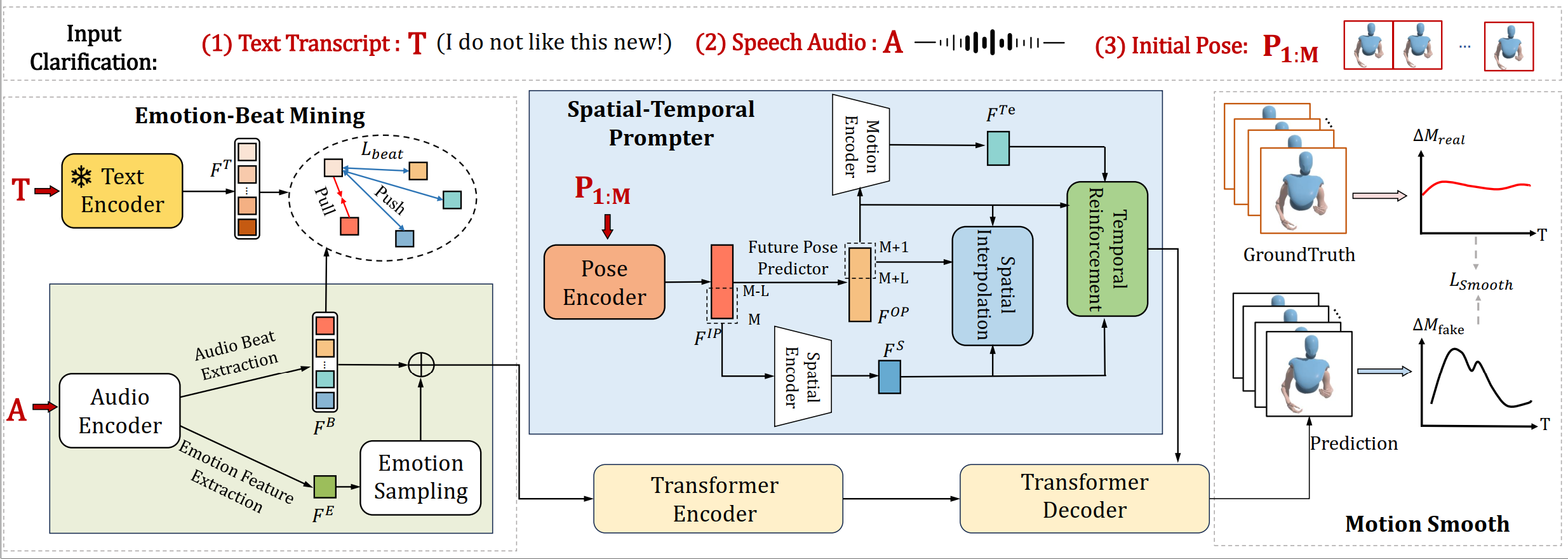
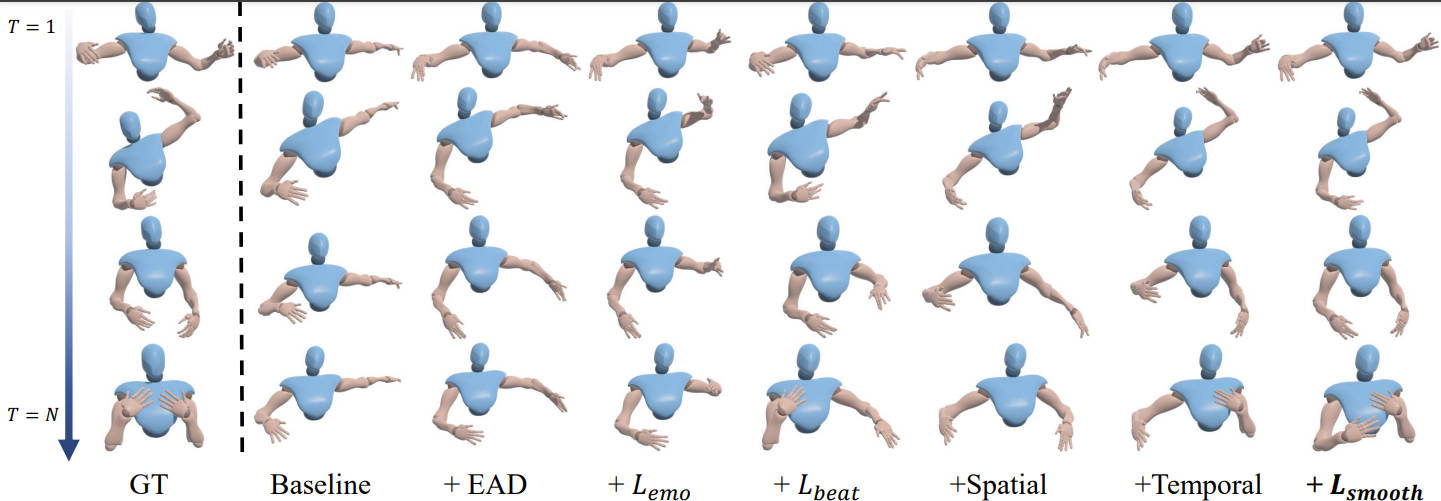
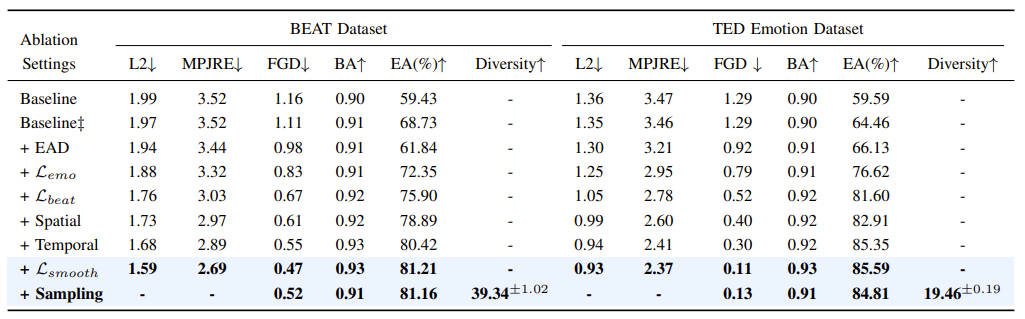
we first develop an Emotion-Beat Mining module (EBM) to extract the emotion and audio beat features as well as model their correlation via a transcript-based visual-rhythm alignment.
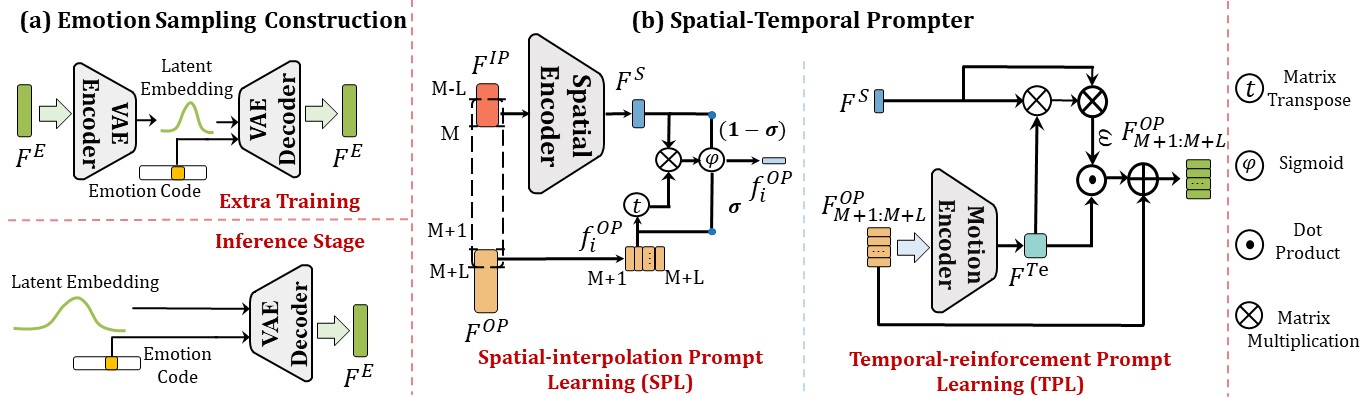
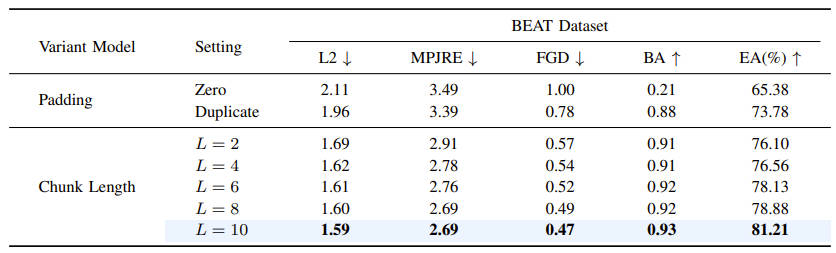
Then, we propose an initial pose based Spatial-Temporal Prompter (STP) to generate future gestures from the given initial poses.
STP effectively models the spatial-temporal correlations between the initial poses and the future gestures, thus producing the spatial-temporal coherent pose prompt.
Once we obtain pose prompts, emotion, and audio beat features, we will generate 3D co-speech gestures through a transformer architecture.
However, considering the poses of existing datasets often contain jittering effects, this would lead to generating unstable gestures.
To address this issue, we propose an effective objective function, dubbed Motion-Smooth Loss.
Specifically, we model motion offset to compensate for jittering ground-truth by forcing gestures to be smooth.
Last, we present an emotion-conditioned VAE to sample emotion features, enabling us to generate diverse emotional results.
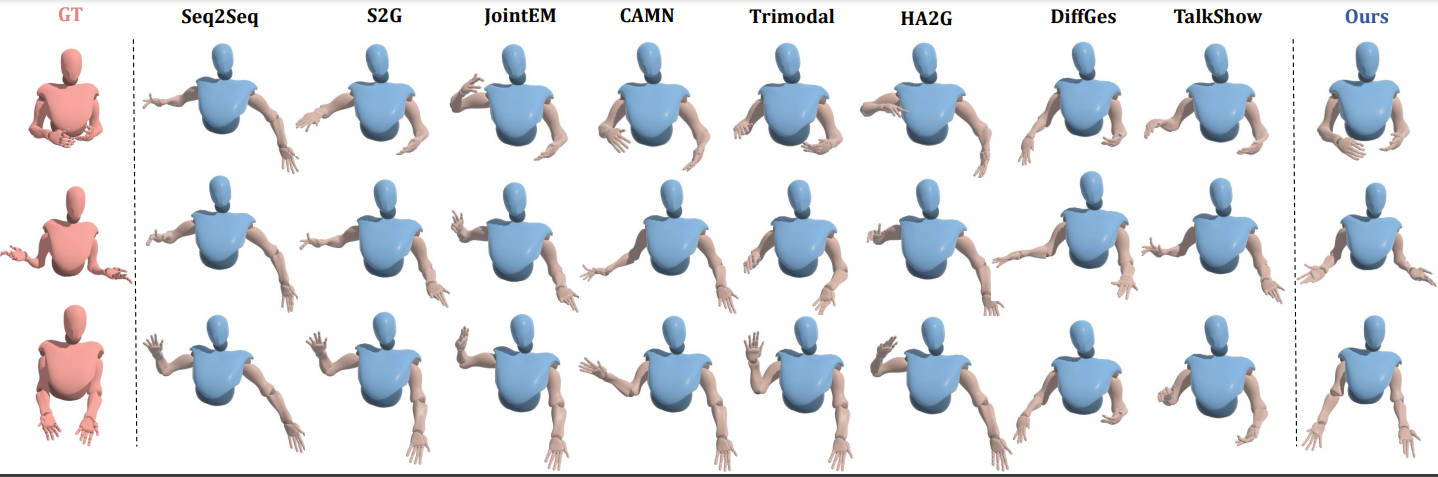
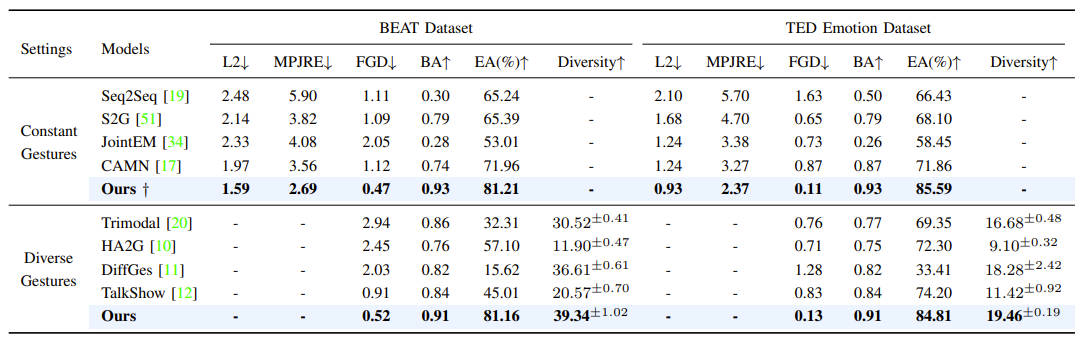
Extensive experiments demonstrate that our framework outperforms the state-of-the-art, achieving vivid and diverse emotional co-speech 3D gestures.